First we need to install all packages, system dependencies and solve conflicts to produce a new renv.lock file.
1.1 Load Libraries
Code
# Run this once to install all the necessary packages# install.packages(c("corrplot", "ggpubr", "caret", "mice", "ROSE", "ranger", "stacks", "tidymodels"))# install.packages("themis")# install.packages("xgboost")# install.packages("gghighlight")# install.packages("dplyr")# install.packages("pscl")# install.packages("parallelly")# install.packages("cli")# install.packages("car")# install.packages("ResourceSelection")
# For data manipulation and visualizationlibrary(tidyverse)library(ggplot2)library(corrplot)library(knitr)library(ggpubr)# For data preprocessing and modelinglibrary(caret)library(mice)library(ROSE) # For SMOTElibrary(ranger) # A fast implementation of random forests# For stacking/ensemble modelslibrary(stacks)library(tidymodels)library(themis)library(gghighlight)library(dplyr)library(pscl)library(car)library(ResourceSelection)# Set seed for reproducibilityset.seed(123)
1.2 Load Data
Will be using my original Dataset as well Steve’s Dataset and compare for differences.
Renan: kaggle_data1 Steve: stroke1
1.2.1 Renan Dataset
Below will be loading the healthcare-dataset-stroke-data.csv and performing necessary changes to the dataset and loading into the DataFrame: kaggle_data1
Code
find_git_root <-function(start =getwd()) { path <-normalizePath(start, winslash ="/", mustWork =TRUE)while (path !=dirname(path)) {if (dir.exists(file.path(path, ".git"))) return(path) path <-dirname(path) }stop("No .git directory found — are you inside a Git repository?")}repo_root <-find_git_root()datasets_path <-file.path(repo_root, "datasets")kaggle_dataset_path <-file.path(datasets_path, "kaggle-healthcare-dataset-stroke-data/healthcare-dataset-stroke-data.csv")kaggle_data1 =read_csv(kaggle_dataset_path, show_col_types =FALSE)# unique(kaggle_data1$bmi)kaggle_data1 <- kaggle_data1 %>%mutate(bmi =na_if(bmi, "N/A")) %>%# Convert "N/A" string to NAmutate(bmi =as.numeric(bmi)) # Convert from character to numeric# Remove the 'Other' gender row and the 'id' columnkaggle_data1 <- kaggle_data1 %>%filter(gender !="Other") %>%select(-id) %>%mutate_if(is.character, as.factor) # Convert character columns to factors for easier modeling
1.2.1 Steve Dataset
Below will be loading the stroke.csv and performing necessary changes to the dataset and loading into the DataFrame: stroke1
Code
# Reading the datafile in (the same one you got for us Renan)#steve_dataset_path <-file.path(datasets_path, "steve/stroke.csv")stroke1 =read_csv(steve_dataset_path, show_col_types =FALSE)# stroke1 <- read.csv("D:\\stroke.csv")
Exploring Dataset so we can plan on how to proceed and possible changes.
Code
# Reveiewing the columns of the data and the dataset size#head(stroke1)nrow(stroke1)#Some data to look at the data in each column#summary(stroke1)count_tables <-lapply(stroke1, table)count_tables
Preparing the Dataset
For each Column…removing the unncessary or unusable variables: 1. Smoking Status - remove unknown 1. bmi - remove N/A 3. Work type - remove children 4. age create numerical variable with 2 places after the decimal 5. gender -remove other
In each column..that has data points that are not usable, recoding those datapoints to become”N/A”
Call:
glm(formula = stroke ~ gender + age + hypertension + heart_disease +
ever_married + work_type + Residence_type + avg_glucose_level +
bmi + smoking_status, family = binomial, data = LR_stroke1)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.426854 0.873243 -9.650 < 2e-16 ***
gender 0.080370 0.167274 0.480 0.630893
age 0.070967 0.006845 10.368 < 2e-16 ***
hypertension 0.570797 0.182580 3.126 0.001770 **
heart_disease 0.417884 0.220311 1.897 0.057856 .
ever_married 0.174316 0.261832 0.666 0.505569
work_type -0.109615 0.126101 -0.869 0.384703
Residence_type 0.005932 0.162188 0.037 0.970822
avg_glucose_level 0.004658 0.001375 3.388 0.000704 ***
bmi 0.006275 0.012875 0.487 0.625954
smoking_status 0.179921 0.106431 1.691 0.090932 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1403.5 on 3356 degrees of freedom
Residual deviance: 1145.4 on 3346 degrees of freedom
AIC: 1167.4
Number of Fisher Scoring iterations: 7
Because, Rsquared and adjusted Rsquared is not appropriated for logistic regression model, to see how model fits and explains variance used alternative
2.1 Evaluating model fit
Evaluating model fit
Comment Oh crap _ McFadden = .18– not a bad fit for logistic regression
Code
# Because, Rsquared and adjusted Rsquared is not appropriated for logistic regression model, to see how model fits and explains variance used alternative##looking at model fit#pR2(model)
Do a confusion matrix for the model by installing Parallelly, and cli, and using caret from the library
comment on confusion matrix =- poor results
Code
# Predict probabilities from the logistic regression modelpredicted_prob <-predict(model, type ="response")# Convert probabilities to binary classes using a 0.5 cutoffpredicted_class <-ifelse(predicted_prob >0.5, 1, 0)
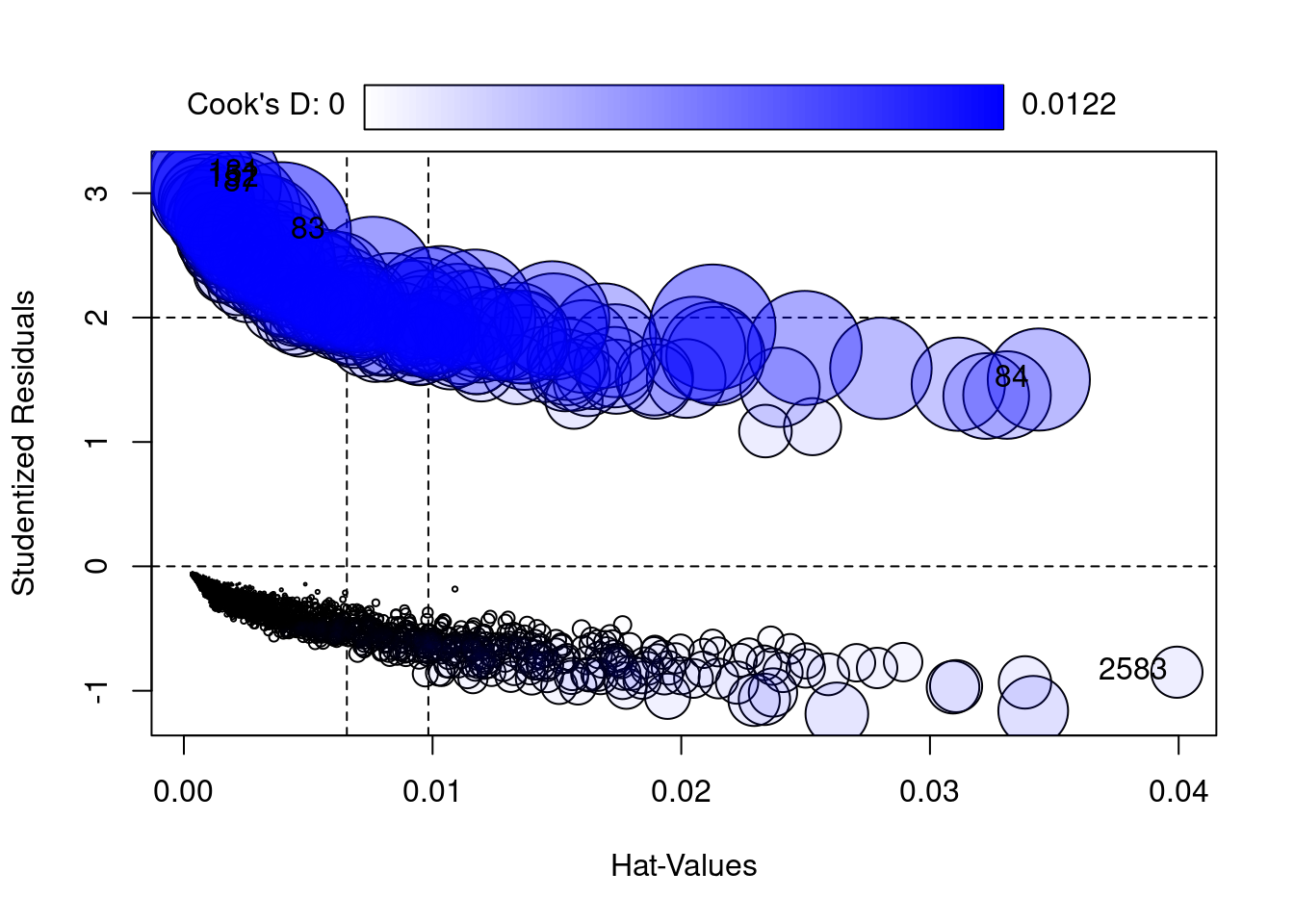
There are several assumptions for Logistic Regression: 1. The Dependent Variable is binary (i.e, 0 or 1) 2. There is a linear relationship between th logit of the outcome and each predictor 3. There are NO high leverage outliers in the predictors 4. There is No high multicollinearity (ie strong correlations) between predictors
Call:
glm(formula = stroke ~ gender + age + hypertension + heart_disease +
ever_married + work_type + Residence_type + avg_glucose_level +
bmi + smoking_status, family = binomial, data = LR_stroke2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.426854 0.873243 -9.650 < 2e-16 ***
gender 0.080370 0.167274 0.480 0.630893
age 0.070967 0.006845 10.368 < 2e-16 ***
hypertension 0.570797 0.182580 3.126 0.001770 **
heart_disease 0.417884 0.220311 1.897 0.057856 .
ever_married 0.174316 0.261832 0.666 0.505569
work_type -0.109615 0.126101 -0.869 0.384703
Residence_type 0.005932 0.162188 0.037 0.970822
avg_glucose_level 0.004658 0.001375 3.388 0.000704 ***
bmi 0.006275 0.012875 0.487 0.625954
smoking_status 0.179921 0.106431 1.691 0.090932 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1403.5 on 3356 degrees of freedom
Residual deviance: 1145.4 on 3346 degrees of freedom
AIC: 1167.4
Number of Fisher Scoring iterations: 7
3.1 Testing Assumption 1
Testing Assumption 1: The Dependent Variable is binary (0 or 1)
Code
unique(LR_stroke2$stroke)
[1] 1 0
3.2 Testing Assumption 2
Testing Assumption 2: There is a linear relationship between the outcome variable and each predictor (use boxTidwell)
For boxTidwell, first adjust all predictors so all values are positive. If we obtain a P value greater than 0.05 it indicates a linear relationship between the predictor and the outcome.
Call:
glm(formula = stroke ~ gender + age + hypertension + heart_disease +
ever_married + work_type + Residence_type + avg_glucose_level +
bmi + smoking_status, family = binomial, data = LR_stroke2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.426854 0.873243 -9.650 < 2e-16 ***
gender 0.080370 0.167274 0.480 0.630893
age 0.070967 0.006845 10.368 < 2e-16 ***
hypertension 0.570797 0.182580 3.126 0.001770 **
heart_disease 0.417884 0.220311 1.897 0.057856 .
ever_married 0.174316 0.261832 0.666 0.505569
work_type -0.109615 0.126101 -0.869 0.384703
Residence_type 0.005932 0.162188 0.037 0.970822
avg_glucose_level 0.004658 0.001375 3.388 0.000704 ***
bmi 0.006275 0.012875 0.487 0.625954
smoking_status 0.179921 0.106431 1.691 0.090932 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1403.5 on 3356 degrees of freedom
Residual deviance: 1145.4 on 3346 degrees of freedom
AIC: 1167.4
Number of Fisher Scoring iterations: 7
Conclusion: age, hypertension, heartdisease, and avg_glucose_level are statistically significant predictors on whether one has a stroke or not.
all the P values of these 4 predictors is .05 or less (note included heart_disease because it approaches statistical significance at .057)
Since this a logistic regression, we cant use R squared and adjusted R squared to see how well the model predicted stroke. So we substitute McFadden’s P value.